Transfer Learning for Deep Learning: An Efficient Time and Cost Saving Technique
- Abhishek Kathuria
- Jul 30, 2020
- 4 min read


Training a neural network has been posing problems for researchers and developers for a long time. There are basically two major problems that arise during the development of DL based solution which are the astronomical costs of training, and the time required to train the network. Since training a neural network includes numerous matrix operations and demands a high computational capability, the cost of operation will escalate if one needs to perform a similar process again for another model. Also, the time to train them escalates at an exponential rate as the networks get deeper and complicated.
Training A network Using GPUs and Cloud Services
Training a neural network using GPU only part of the solution. Using GPUs is one effective way to speed up the process. GPUs have high-speed random-access memory with a high number of cores for high-performance computing. While it reduces the time to train a model, however, seeing the price of GPUs, it is simply not a viable solution.
Another way to train their models is by using cloud services like google cloud platform and Amazon Web Services (AWS). This helps in avoiding to buy a GPU because cloud platforms give access to online GPUs. But again, training a network for a long time can burn a hole in your pocket by running up a huge electricity bill.
To counter this problem of time and cost in training a deep learning model, the practice of Transfer Learning was introduced. This learning methodology takes a leap further in training networks by training a model faster consuming less time.
How does Transfer Learning Work for Deep Learning?
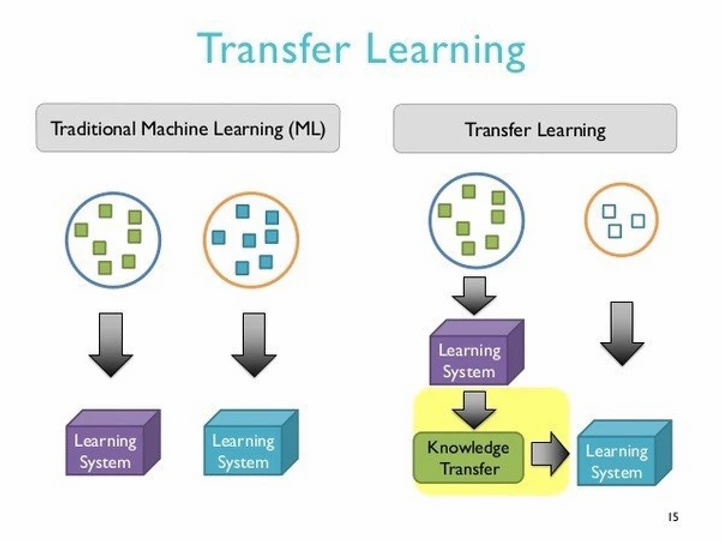
Transfer Learning focuses on storing the knowledge or weights of the neural network from a trained architecture so that it can be reused to train another model for a further task. Essentially, it is using an existing solution to a new problem.
Put simply, we first train a base network on a base dataset and task, and then we re-purpose the learned features, or transfer them, to a second target network (to be trained on a target dataset and task). In this, a neural network is trained on a dataset, the weights of its connections are extracted and then transferred to any other neural network. What happened here is that, instead of training the other neural network from scratch, we “transfer” the learned features.
Understanding Pre-Trained Models

In Transfer Learning, the use of the pre-trained models is very famous among researchers and developers. A pre-trained model is nothing but a trained neural network in a particular task. So, instead of training a network from scratch, these pre-trained models can be used as a starting point for solving other similar problems. Let’s understand this through an example. If we want to build an OCR, we can either train a CNN model from scratch or take pre-trained models and boost its accuracy.
By considering a pre-trained model, one can save huge efforts required to re-invent the wheel. All we need to focus is on the tuning of the network according to our task.
Different Ways Transfer Learning is Used.
Feature extraction
Pre-Trained models can be used for feature extractions by removing the output layers of the network, and then connecting it to some other architecture.
Using the entire Architecture of model
We can use the layer orientation of the pre-trained network with random weights initialized and train it according to our task.
Partial training of the network
We can also train the network in such a way that only some layers are trained and the rest aren’t. This can be done by keeping the weights constant of the layers that you don’t want to train.
When and How to use Transfer Learning?
What kind of Transfer Learning you use depends on several factors, but the most important ones are the size of the new dataset and its similarity to the original dataset on which your existing model was trained. This leads us to the existence of four major scenarios:
Scenario 1: The new dataset is small and similar to the original dataset
As the data is small, it won’t be a good idea to fine tune the network as it would lead to overfitting.
Scenario 2: The new dataset is large and similar to the original dataset
As we have more data, we can fine-tune the network without the fear of overfitting.
Scenario 3: The new dataset is small but very different from the original dataset
As the dataset is different from the original, it won’t be good to rely on the feature extraction of the higher layers as the layers will have dataset-specific features.
Scenario 4: The new dataset is large and very different from the original dataset
As the dataset is large, we can train the network by initializing weights equal to weights of the pre-trained network. In this case, we will have enough data to fine-tune the entire network.

Examples of Transfer Learning with Deep Learning
It is very common to apply Transfer Learning for image and text data since using the unstructured forms of data for training neural networks to require a great deal of time. For example, in the ImageNet dataset — which is a 1000 class image classification
competition, it is difficult to train a model from scratch. The reason is its sheer volume of data and, also, the complexity of the architecture which would be required to train it. So, for this kind of problem, some organizations have made their pre-trained models available online for public use under a permissive license.
These include:
These models can be downloaded and incorporated directly into new models that expect image data as input.
However, in the case of Language data, finding word embeddings can be a long and tedious task. (Word embedding refers to a mapping of words to a high-dimensional continuous vector space where different words with a similar meaning have a similar vector representation.) Research organizations tend to release pre-trained models trained on a very large corpus of text documents to find these embedding under a permissive license.
Some of the well-known pre-trained language models available for are:
The above models can be downloaded and incorporated directly into new models that expect the same kind of data as input.



Comments